The Browser Bookmark Problem
I've been looking for a better way to bookmark useful content I find on the web. I've got a number of bookmarks stored in Firefox, but I find that I rarely look through them. Occasionally when I do, I'm surprised to find something interesting that I had completely forgotten about. Even when I know I have something bookmarked somewhere, I tend to just run a web search for the topic I wanted to read about and search through the results until I see one that looks familiar. For whatever reason I haven't updated my workflow to check my bookmarks.
Also, after adding a number of bookmarks they start to feel cumbersome. Like I'm just collecting these links without a good way to organize them or search through them later. I have them in folders but, still...
A Solution?
I while back I came across a post on Hacker News where someone was asking about bookmarking services. The top reply to that post was from a user called "l72" talking about how they setup search engine software called YaCy to act as a bookmarking service. Instead of actually saving a bookmark for an interesting web page, this user would instruct YaCy to index the page into the search engine. This has a few benefits:
- The webpage is saved for later, similarly to a bookmark.
- The list of "bookmarks" is searchable using an actual search engine.
- YaCy can cache each indexed page, which means if the website goes offline or later changes, YaCy preserves a copy the way it was when you indexed it.
This idea really resonated with me and I thought I would revisit it when I had some time. Well, I recently had some time.
What is YaCy?
YaCy is free software for your own search engine. The source code is available on GitHub. YaCy is designed to be a distributed peer-to-peer search engine. In theory, there could be hundreds or thousands of YaCy instances all over the world, each indexing content based on how its owner configures that particular instance. A user can then use one instance to search content indexed by all of the peered instances. Rather than having a single corporate entity (Google, Bing, etc) scrape the entire Internet, you can have many independent users scraping different pieces and then make the whole thing searchable.
I find the idea really cool, though for my current use-case I don't want my personal search engine to be publicly accessible. There's a good chance I'll want to index some content that I don't want publicly searchable (my personal notebook, for example). Luckily, you can configure YaCy as a "private peer" and disable peering to achieve such a configuration.
A Helping Hand
When I decided to dive into this project a week or so ago, I went searching the web for references to using a search engine as a bookmarking service. I had to search the web because... I hadn't bookmarked the original Hacker News post. Go figure. After a bit of searching I found the post and once I remembered the name "YaCy" I dug some more.
Eventually I found an extremely helpful post on Keyhan Vahil's blog. Keyhan has configured YaCy as their own personal search engine in a very similar way to the Hacker News user. Keyhan had set it up similarly to how I would do it and published all the steps they took to get it online. This was a perfect starting place for me.
In fact, I followed most of the guide exactly as written. I won't republish the instructions here, but I will list a high level configuration overview. Then I'll discuss some differences I made to my own configuration.
Configuration
- Hardware
- I'm using the cheapest Digital Ocean droplet available right now ($6/month).
- Reverse Proxy
- I use Caddy exactly as described in Keyhan's post.
- Containerization
- I'm using Docker compose, again the same as Keyhan.
- YaCy
- YaCy is configured in Robinson mode as a "private peer", as described in Keyhan's post.
Indexing Websites on Desktop
With the search engine up and running, I needed to start indexing content. Keyhan uses a web browser user script to automatically index every single web page visited. Not only that, but Keyhan's script sets the indexing depth=1, which means that YaCy will also index every web page linked from the original submitted URL.
I found this idea intriguing in that I could have an index of every web page I've ever seen. It would make it easy for me to go find a web page if I ever think, "I know I read something about that somewhere...". However, I ultimately decided it was overkill and I try to avoid becoming a digital hoarder. I only wanted to index specific pages if I actually enjoyed the content, similar to a traditional bookmark. If I want to search through a bunch of results to find what I'm after, I can use a regular search engine for that. I want my personal engine to hold only quality content, curated by myself. I also wanted to index with depth=0 as the default, meaning that only the original URL would be indexed. I don't want to index a bunch of links that I haven't even seen.
I ended up modifying Keyhan's user script to allow me to press a key combination to index a specific page.
// ==UserScript==
// @name YaCyIndexer
// @namespace https://richardosgood.com
// @description Index specific pages with YaCy.
// @version 0.1
// @match *://*/*
// @grant GM_xmlhttpRequest
// @grant GM_log
// @grant GM_notification
// @require https://cdn.jsdelivr.net/npm/@violentmonkey/shortcut@1
// ==/UserScript==
const YACY_HOST = 'https://<YACY URL>';
const ADMIN_PASSWORD = '<ADMIN PASSWORD>';
const yacyUrl = new URL('/Crawler_p.html', YACY_HOST);
const url = new URL(window.location);
VM.shortcut.register('c-e', () => {
console.log("triggered");
yacyIndex();
});
function yacyIndex() {
// Don't try to index YaCy from YaCy.
if (url.host === yacyUrl.host) return;
// Strip out potentially sensitive parts of the URL.
url.search = '';
url.hash = '';
yacyUrl.search = new URLSearchParams({
crawlingstart: '',
crawlingMode: 'url',
crawlingURL: url.toString(),
crawlingDepth: '0',
range: 'width',
deleteold: 'off',
recrawl: 'reload',
reloadIfOlderNumber: '7',
reloadIfOlderUnit: 'day',
indexText: 'on',
indexMedia: 'on',
// Check API documentation for other parameters!
// https://wiki.yacy.net/index.php/Dev:APICrawler
});
GM_xmlhttpRequest({
method: 'GET',
url: yacyUrl.toString(),
onload: (response) => {
GM_log('YaCy gave us a response', response.status);
if (response.status == 200) {
GM_notification("Success", "YaCy", "", null);
} else {
GM_notification("Indexing failed: " + response.status, "YaCy", "", null);
}
},
onerror: (response) => {
GM_log('YaCy error requesting crawl', response.status);
GM_notification("Indexing failed", "YaCy", "", null);
},`
user: 'admin',
password: ADMIN_PASSWORD,
});
}
The above user script is Keyhan's script with a couple modifications. For one, the crawlingDepth parameter is set to zero to avoid indexing any other pages. Also, this script is configured to index pages when I press CTRL+e. It seems to work well after testing it out a bit.
Indexing Websites on Android
After having YaCy up and running a few days, I found that I often find interesting content when browsing on my Android phone. Sometimes when I'm bored or need a break, I'll scroll through Hacker News or Twitter or something and come across a really good resource that I want to save for later. The problem is that the above user script wouldn't work for me on Android. Firefox's Android application wouldn't let me install the Violent Monkey extension, and even if I could, I wouldn't be able to press CTRL+e with my touch screen. I needed some other way to trigger YaCy to index a URL. Preferably something simple with minimal taps required.
I eventually decided to write my own Android App to solve this problem. The app has a configuration screen where I can set the YaCy URL and YaCy credentials. I can also configure a default indexing depth. The home screen has a text input for a URL and a slider to choose an indexing depth if I want to change from the default setting. Then I just press "Index This!" to index the URL.
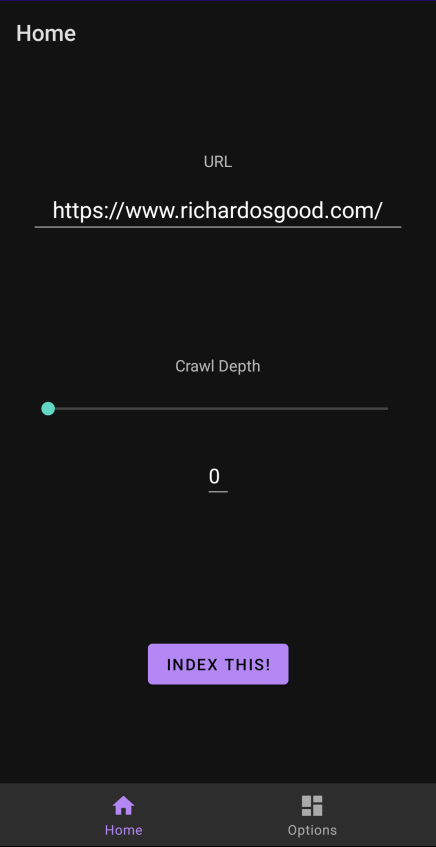
While that works, it's cumbersome to have to copy and paste a URL into a second app every time I want to save something for later. So instead, when I find something in Firefox mobile, I can just hit the "share" button in the browser. This brings up a list of applications which now includes my IndexThis app. Clicking on IndexThis will launch the application and automatically fill in the URL with whatever I was looking at in Firefox. I can then simply press "Index This!" To index it. The whole process takes four taps. It's more than I'd prefer, but it's absolutely usable and it doesn't get in my way.
I've made IndexThis available on GitHub for anyone else who may find it useful. It's not pretty, but it gets the job done for me. If you like it, feel free to send me an email and let me know. If you want to help improve the app, feel free to make a pull request.
Searching YaCy
I added YaCy to all of my browsers as a search engine option. Now I can specifically search my YaCy instance by beginning my query with "!y". Now I need to focus on updating my workflow to remember to check there sometimes. I'm so used to just searching a topic in the address bar and skimming the results. I'm not used to thinking about "which engine do I want to use for this specific query? I just want to type something in and have the results pop up.
Future Ideas
I think this will be a great resource for me, but only time will tell. My biggest concern is that I'll often forget to search YaCy and I'll end up with a bunch of bookmarked pages I never reference.
One idea I have is to write a custom search page that will take my query and simultaneously search my normal search engine (Kagi) and also YaCy at the same time. It would have to somehow show me results from both. I'm not exactly sure how this would work or even look, but I feel like there might be something to it. Maybe it could simply load the results in two frames on a single tabbed page? It would hopefully be enough just to remind me that there may be results from my own search engine for any given query.
I'll have to post an update if I figure out a good solution.